Ở bài trước mình đã trình diễn định nghĩa và một vài ứng dụng của máy học (Machine Learning – ML), riêng biệt ML với Trí tuệ tự tạo (Artificial Intelligence – AI) cũng tương tự mối quan hệ giới tính giữa AI, ML và Big Data. Từ nội dung bài viết này trở đi bản thân sẽ triệu tập viết về ML, những thuật toán, cách áp dụng công cố gắng kèm theo một vài ba demo bé dại giúp bạn đọc dễ tưởng tượng và áp dụng. Để bắt đầu cho chuỗi nội dung bài viết sắp tới, lúc này mình sẽ trình diễn cách phân nhóm những thuật toán ML.
Bạn đang xem: Các thuật toán học có giám sát
Với đa số mọi người, trước khi bắt đầu giải quyết một vấn đề nào đó, việc thứ nhất là bọn họ sẽ tò mò xem liệu có ai đã gặp vụ việc này hoặc vấn đề tựa như như vậy hay không và biện pháp họ xử lý thế nào. Sau thời điểm nắm được thông tin khái quát, quá trình kế tiếp là chọn lựa và điều chỉnh giải pháp sao cho tương xứng với vụ việc của bản thân. Vào trường hợp vấn đề còn quá mớ lạ và độc đáo thì họ mới phải bắt tay làm cho từ đầu, điều này phần nhiều rất hiếm, nhất là trong thời đại công nghệ này, khi mà chỉ bởi một cú nhấp chuột, hàng ngàn thông tin, bốn liệu về đề tài chúng ta quan trung khu sẽ xuất hiện. Cũng như thế, ML hiện đã được nghiên cứu rộng khắp, rất nhiều công trình khoa học, thuật toán được đã cho ra đời. Với người mới bắt đầu mà nói thì bọn họ chưa bắt buộc phải làm những gì cả ngoài việc nắm được các thuật toán cơ bản, điểm sáng của chúng để khi đối lập với một bài xích toán ví dụ trong thực tế bạn có thể biết được mình cần lựa lựa chọn thuật toán nào cho tương xứng đã là điều cực tốt rồi.
Mặc dù có tương đối nhiều thuật toán học tập nhưng phụ thuộc vào phương thức học tập (learning style) hoặc sự tương đồng (similarity) về hiệ tượng hay tác dụng mà chúng rất có thể được gom thành từng nhóm. Dưới đây mình sẽ trình bày tổng quan liêu cả hai phương pháp phân nhóm thuật toán học này.
1. Phân nhóm dựa trên phương thức họcXét theo cách tiến hành học, các thuật toán ML được chia thành bốn nhóm, bao hàm “Học tất cả giám sát” (Supervised Learning), “Học ko giám sát” (Unsupervised Learning), “Học buôn bán giám sát” (hay học phối hợp - Semi-supervised Learning) cùng “Học tăng cường” (Reinforcement Learning).
a. Học bao gồm giám sát
Học có thống kê giám sát hay có cách gọi khác là học tất cả thầy là thuật toán dự kiến nhãn (label)/đầu ra (output) của một dữ liệu mới dựa vào tập dữ liệu đào tạo và huấn luyện mà trong các số ấy mỗi mẫu tài liệu đều đã có gán nhãn như minh hoạ sinh sống Hình 1. Lúc đó, thông qua 1 quá trình huấn luyện, một quy mô sẽ được xây dựng để cho ra những dự đoán cùng khi những dự đoán bị sai thì mô hình này đang được tinh chỉnh lại. Việc đào tạo và huấn luyện sẽ tiếp tục cho đến khi mô hình đạt được nấc độ chính xác mong mong muốn trên tài liệu huấn luyện. Điều này cũng giống như khi họ đi học tập trên lớp, ta biết câu trả lời đúng mực từ giáo viên (tập dữ liệu có nhãn) cùng từ kia ta sẽ sửa chữa thay thế nếu có tác dụng sai. Học có đo lường và tính toán là nhóm thịnh hành nhất trong các thuật toán ML.
Hình 1: Supervised Learning Algorithms
Một biện pháp toán học, học có tính toán là khi bọn chúng ra có một tập hợp biến đầu vào $ X=x_1,x_2,…,x_N $ cùng một tập phù hợp nhãn khớp ứng $ Y=y_1,y_2,…,y_N $, trong số ấy $ x_i$, $y_i $ là các vector. Các cặp tài liệu biết trước $( x_i, y_i ) in X imes Y $ được điện thoại tư vấn là tập dữ liệu huấn luyện và đào tạo (training data). Từ tập dữ liệu đào tạo và huấn luyện này, họ cần tạo ra một hàm số ánh xạ mỗi bộ phận từ tập X sang một phần tử (xấp xỉ) tương xứng của tập Y:
$$ y_i approx f(x_i), forall i=1, 2, …, N $$
Mục đích là dao động hàm số $f$ thật giỏi để khi bao gồm một tài liệu x mới, chúng ta cũng có thể tính được nhãn khớp ứng của nó $y=f(x)$.
Ví dụ: Trong nhấn dạng chữ số viết tay, ta có ảnh của hàng nghìn trường hợp ứng với từng chữ số được viết bởi đa số người khác nhau. Ta đưa những bức ảnh này vào trong 1 thuật toán học cùng chỉ đến nó biết “mỗi bức ảnh tương ứng với chữ số nào”. Sau khi thuật toán tạo thành một mô hình, có nghĩa là một hàm số nhấn đầu vào là một bức ảnh và đến ra hiệu quả là một chữ số. Khi nhận thấy một bức hình ảnh mới mà quy mô “chưa từng gặp mặt qua” với nó sẽ dự kiến xem bức hình ảnh đó tương ứng với chữ số nào.
Hình 2: Ảnh minh hoạ đến tập tài liệu chữ số viết tay - MNIST
Đối với phần đa ai sử dụng social Facebook thì khá thân thuộc với chức năng phát hiện tại khuôn khía cạnh trong một bức ảnh, thực chất của thuật toán dò tìm các khuôn phương diện này là 1 trong những thuật toán học có giám sát với tập huấn luyện và đào tạo là vô số ảnh đã được gán nhãn là mặt người hay là không phải mặt người.
Các thuật toán học tập có đo lường còn được phân ra thành hai loại chính là phân lớp (Classification) với hồi quy (Regression).
Phân lớp
Một vấn đề được điện thoại tư vấn là phân lớp nếu các nhãn của dữ liệu đầu vào được tạo thành một số hữu hạn lớp (miền giá trị là tránh rạc). Chẳng hạn như tính năng xác minh xem một thư điện tử có bắt buộc là spam hay là không của Gmail; xác định xem hình ảnh của con vật là chó tốt mèo. Hoặc ví dụ nhận dạng cam kết số viết tay sống trên cũng thuộc câu hỏi phân lớp, bao gồm mười lớp ứng với các số tự 0 đến 9. Tương tự như cho ví dụ thừa nhận dạng khuôn phương diện với nhì lớp là đề nghị và không phải khuôn mặt, …
Hồi quy
Một bài toán được xem như là hồi quy giả dụ nhãn ko được phân thành các team mà là một giá trị thực ví dụ (miền cực hiếm là liên tục). Hầu như các việc dự báo (giá cổ phiếu, giá bán nhà, …) hay được xếp vào bài toán hồi quy. Ví như, nếu 1 căn nhà rộng 150 m^2, có 7 phòng và giải pháp trung tâm tp 10 km sẽ có giá là bao nhiêu? bây giờ kết quả dự kiến sẽ là một vài thực.
Nếu như phát hiện tại khuôn mặt là việc phân lớp thì dự kiến tuổi là vấn đề hồi quy. Tuy nhiên dự đoán tuổi cũng có thể coi là phân lớp nếu ta cho tuổi là một số trong những nguyên dương N và khi ấy ta sẽ sở hữu được N lớp khác nhau tính từ 1.Một số thuật toán khét tiếng thuộc về nhóm học có giám sát và đo lường như:
Phân lớp: k-Nearest Neighbors, mạng nơron nhân tạo, SVM, …
Hồi quy: Linear Regression, Logistic Regression, …
b. Học tập không giám sát
Trái với Supervised learning, học không giám sát và đo lường hay học không thầy là thuật toán dự đoán nhãn của một tài liệu mới dựa trên tập dữ liệu đào tạo mà trong đó tất cả các mẫu dữ liệu đều chưa được gán nhãn hay có thể nói là ta đo đắn câu trả lời đúng chuẩn cho mỗi dữ liệu đầu vào như minh hoạ sinh sống Hình 3. Điều này cũng tương tự khi ta học mà không tồn tại thầy cô, sẽ không có bất kì ai cho ta biết đáp án và đúng là gì.
Hình 3: Unsupervised Learning Algorithms
Khi đó, mục tiêu của thuật toán unsupervised learning không phải là kiếm tìm đầu ra đúng đắn mà sẽ hướng tới việc tra cứu ra cấu trúc hoặc sự liên hệ trong dữ liệu để tiến hành một các bước nào đó, ví như gom cụm (clustering) hoặc giảm số chiều của dữ liệu (dimension reduction) để dễ dàng trong việc tàng trữ và tính toán.
Các việc Unsupervised learning tiếp tục được chia nhỏ tuổi thành hai nhiều loại là phân nhiều (Clustering) cùng luật phối kết hợp (Association Rule).
Phân cụm
Một câu hỏi phân cụm / phân nhóm cục bộ dữ liệu X thành các nhóm/cụm nhỏ tuổi dựa trên sự tương quan giữa những dữ liệu trong những nhóm. Ví dụ như phân nhóm khách hàng dựa vào độ tuổi, giới tính. Điều này cũng tương tự việc ta đưa cho 1 đứa trẻ không ít mảnh ghép với các hình dạng và color khác nhau, có thể là tam giác, vuông, tròn với màu xanh, đỏ, tím, vàng, kế tiếp yêu mong trẻ phân chúng thành từng nhóm. Tuy nhiên ta không dạy dỗ trẻ mảnh nào tương xứng với hình nào hoặc màu nào, tuy nhiên nhiều khả năng trẻ vẫn rất có thể phân loại những mảnh ghép theo màu sắc hoặc hình dạng.
Luật kết hợp
Là câu hỏi mà khi chúng ta muốn tìm hiểu ra một quy luật dựa trên nhiều tài liệu cho trước. Ví như những người tiêu dùng mua sản phẩm này sẽ tải thêm món đồ kia; hoặc khan đưa xem phim này sẽ có được xu hướng đam mê xem phim kia, phụ thuộc đó ta rất có thể xây dựng phần đông hệ thống gợi nhắc khách hàng (Recommendation System) nhằm mục đích thúc đẩy nhu cầu buôn bán hoặc xem phim….
Một số thuật toán thuộc team học không tính toán như Apriori (Association Rule), k-Means (Clustering), …
c. Học phân phối giám sát
Là câu hỏi mà lúc tập dữ liệu đầu vào X là lếu láo hợp những mẫu tất cả nhãn và không có nhãn, trong đó số lượng có nhãn chỉ chiếm 1 phần nhỏ như minh hoạ nghỉ ngơi Hình 4.
Phần lớn các bài toán thực tiễn của ML thuộc nhóm này vày việc thu thập dữ liệu có nhãn tốn rất nhiều thời gian với có chi phí cao. Không hề ít loại dữ liệu thậm chí cần phải có chuyên gia mới gán nhãn được, chẳng hạn như ảnh y học tập hoặc các cặp câu tuy vậy ngữ. Ngược lại, dữ liệu chưa tồn tại nhãn hoàn toàn có thể được thu thập với chi tiêu thấp trường đoản cú internet.
Hình 4: Semi-supervised Learning Algorithms
Với câu hỏi này, mô hình phải khám phá các cấu tạo để tổ chức triển khai dữ liệu cũng giống như đưa ra dự đoán. Vì đặc điểm trung gian buộc phải ta rất có thể sử dụng unsupervised learning để mày mò và tìm kiếm hiểu kết cấu trong dữ liệu đầu vào, đồng thời thực hiện supervised learning để tham dự đoán cho dữ liệu không được gán nhãn. Tiếp nối đưa dữ liệu vừa dự đoán quay lại làm dữ liệu đào tạo và huấn luyện cho supervised learning cùng sử dụng quy mô sau lúc huấn luyện để lấy ra dự đoán về tài liệu mới.
Một số thuật toán học tăng cường như: Self Training, Generative models, S3VMs, Graph-Based Algorithms, Multiview Algorithms, …
d. Học tăng cường
Học tăng tường hay học củng chũm là bài toán giúp cho một hệ thống tự động hóa xác định hành động dựa trên yếu tố hoàn cảnh để đạt được lợi ích cao nhất. Hiện tại, reinforcement learning chủ yếu được vận dụng vào định hướng Trò đùa (Game Theory), những thuật toán cần xác định nước đi tiếp sau để có được điểm số cao nhất. Hình 5 là một trong những ví dụ đơn giản và dễ dàng sử dụng học tăng cường.
Hình 5: Minh hoạ đến học bức tốc được vận dụng trong kim chỉ nan trò chơi.
Alpha
Go - 1 phần mềm chơi cờ vây trên máy vi tính được xây dựng do Google Deep
Mind hay chương trình dạy máy tính xách tay chơi game Mario là đầy đủ ứng dụng thực hiện học tăng cường.
Cờ vậy được coi là trò chơi gồm độ phức tạp rất là cao với tổng thể nước đi là giao động 1076110761, đối với cờ vua là 1012010120, vày vậy thuật toán phải chọn ra một nước đi tối ưu trong số hàng tỉ tỉ lựa chọn. Về cơ bản, Alpha
Go bao hàm các thuật toán trực thuộc cả Supervised learning cùng Reinforcement learning. Trong phần Supervised learning, dữ liệu từ các ván cờ vày con tín đồ chơi cùng nhau được đưa vào để huấn luyện. Tuy nhiên, mục tiêu sau cuối của Alpha
Go chưa phải là nghịch như con tín đồ mà đề xuất thắng được nhỏ người. Do vậy, sau khi học hoàn thành các ván cờ của bé người, Alpha
Go tự chơi với chủ yếu nó trải qua hàng triệu ván cờ để tìm ra những nước đi new tối ưu hơn. Thuật toán vào phần tự nghịch này được xếp vào nhiều loại Reinforcement learning.
Đơn giản hơn cờ vây, tại một thời điểm cố gắng thể, người chơi game Mario chỉ việc bấm một vài lượng nhỏ các nút (di chuyển, nhảy, bắn đạn) hoặc không nên bấm nút nào ứng cùng với một chướng ngại vật thắt chặt và cố định ở một vị trí thay định. Lúc ấy thuật toán trong ứng dụng dạy máy tính chơi game Mario đang nhận nguồn vào là sơ đồ gia dụng của màn hình tại thời gian hiện hành, trách nhiệm của thuật toán là tìm ra tổ hợp phím phải được bấm ứng với đầu vào đó. Việc đào tạo và huấn luyện này được dựa vào điểm số mang đến việc dịch rời được bao xa với thời hạn bao thọ trong game, càng xa và càng sớm thì điểm thưởng dành được càng cao, tất nhiên điểm thưởng này sẽ không phải là điểm của trò nghịch mà là điểm do chính bạn lập trình tạo thành ra. Thông qua huấn luyện, thuật toán vẫn tìm ra một biện pháp tối ưu nhằm tối đa phần điểm trên, qua đó đã có được mục đích sau cuối là cứu giúp công chúa.
Có những cách khác biệt để thuật toán rất có thể mô hình hóa một sự việc dựa bên trên sự ảnh hưởng của nó với dữ liệu đầu vào. Phân loại hoặc cách tổ chức triển khai thuật toán học vật dụng này rất có lợi vì nó buộc bọn họ phải quan tâm đến về mục đích của dữ liệu đầu vào với quy trình sẵn sàng mô hình và lựa chọn một thuật toán phù hợp nhất cho vụ việc của chúng ta để có công dụng tốt nhất.
2. Phân nhóm dựa vào sự tương đồngDựa vào sự tương đồng về chức năng hay phương thức hoạt hễ mà các thuật toán sẽ tiến hành gom nhóm với nhau. Sau đây là danh sách những nhóm và các thuật toán theo từng nhóm.
a. Các thuật toán hồi quy (Regression Algorithms)
Hồi quy là quá trình tìm côn trùng quan hệ phụ thuộc vào của một biến chuyển (được điện thoại tư vấn là biến phụ thuộc hay trở nên được giải thích, biến đổi được dự báo, biến chuyển được hồi quy, trở thành phản ứng, biến đổi nội sinh) vào một trong những hoặc nhiều biến chuyển khác (được call là biến đổi độc lập, biến giải thích, biến dự báo, đổi mới hồi quy, trở thành tác nhân hay vươn lên là kiểm soát, trở nên ngoại sinh) nhằm mục tiêu mục đích ước lượng hoặc tiên đoán quý hiếm kỳ vọng của biến phụ thuộc khi biết trước giá trị của đổi mới độc lập. Hình 6 thay mặt cho ý tưởng của các thuật toán hồi quy.
Ví dụ như, dự kiến rằng nếu như tăng lãi suất tiền nhờ cất hộ thì sẽ huy động được lượng tiền gửi nhiều hơn, khi đó ngân hàng A cần phải biết mối quan hệ giữa lượng tiền giữ hộ và lãi suất vay tiền gửi, ví dụ hơn họ có nhu cầu biết lúc tăng lãi vay thêm 0.1% thì lượng chi phí gửi sẽ tăng trung bình là bao nhiêu.
Các thuật toán hồi quy thông dụng nhất là:
Linear Regression
Logistic Regression
Locally Estimated Scatterplot Smoothing (LOESS)
Multivariate Adaptive Regression Splines (MARS)
Ordinary Least Squares Regression (OLSR)
Stepwise Regression
Hình 6: Regression Algorithms
b. Thuật toán dựa vào mẫu (Instance-based Algorithms)
Mô hình học tập dựa trên mẫu giỏi thực thể là bài toán ra quyết định phụ thuộc vào các trường hòa hợp hoặc các mẫu dữ liệu huấn luyện và giảng dạy được coi là quan trọng giỏi bắt buộc đối với mô hình.
Nhóm thuật toán này thường desgin cơ sở tài liệu về tài liệu mẫu và đối chiếu dữ liệu mới với cửa hàng dữ liệu bằng phương pháp sử dụng thước đo tương tự để tìm kiếm kết quả tương xứng nhất và đưa ra dự đoán. Lúc đó trung tâm được đặt vào thay mặt đại diện của các thể hiện tại được lưu trữ như minh hoạ nghỉ ngơi Hình 7.
Hình 7: Instance-based Algorithms
Các thuật toán dựa vào thực thể phổ biến nhất là:
k-Nearest Neighbor (k
NN – k trơn giềng sát nhất)
Learning Vector Quantization (LVQ)
Locally Weighted Learning (LWL)
Self-Organizing bản đồ (SOM)
c. Thuật toán chuẩn chỉnh hoá (Regularization Algorithms)
Các thuật toán chuẩn chỉnh hoá thành lập từ sự mở rộng các phương thức đã có (điển hình là các phương thức hồi quy) bằng cách xử phân phát các mô hình dựa trên mức độ tinh vi của chúng. Bài toán ưu tiên các mô hình đơn giản hơn cũng giỏi hơn trong vấn đề khái quát lác hóa. Hình 8 tượng trưng cho ý tưởng của thuật toán chuẩn hoá.
Hình 8: Regularization Algorithms
Các thuật toán thiết yếu quy thông dụng nhất là:
Elastic Net
Least Absolute Shrinkage & Selection Operator (LASSO)
Least-Angle Regression (LARS)
Ridge Regression
d. Thuật toán cây quyết định (Decision Tree Algorithms)
Đây là phương pháp xây dựng mô hình ra ra quyết định dựa trên những giá trị thực của không ít thuộc tính trong dữ liệu. Sự quyết định được rẽ nhánh trong cấu trúc cây cho tới khi ra quyết định dự đoán được chỉ dẫn cho một mẫu nhất định như minh hoạ sinh hoạt Hình 9. Phương thức này được thực hiện trong việc đào tạo và giảng dạy dữ liệu cho câu hỏi phân lớp cùng hồi quy. Vị sự nhanh chóng, đúng đắn nên cách thức này rất rất được quan tâm trong ML.
Hình 9: Decision Tree Algorithms
Các thuật toán cây quyết định thịnh hành nhất bao gồm:
Chi-squared Automatic Interaction Detection (CHAID)
Classification cùng Regression Tree – CART
Conditional Decision Trees
C4.5 cùng C5.0
Decision Stump
Iterative Dichotomiser 3 (ID3)
M5
e. Thuật toán Bayes (Bayesian Algorithms)
Đây là nhóm những thuật toán vận dụng Định lý Bayes cho bài toán phân loại và hồi quy.
Hình 10: Bayesian Algorithms
Các thuật toán phổ cập nhất là:
Averaged One-Dependence Estimators (AODE)
Bayesian Belief Network (BBN)
Bayesian Network (BN)
Gaussian Naive Bayes
Multinomial Naive Bayes
Naive Bayes
f. Thuật toán phân cụm (Clustering Algorithms)
Tất cả các cách thức đều thực hiện các kết cấu vốn tất cả trong dữ liệu để tổ chức tốt nhất có thể dữ liệu thành các nhóm có mức độ phổ biến tối đa nhờ vào trọng trọng tâm (centroid) và thứ bậc (hierarchal) như thể hiện ở Hình 11.
Hình 11: Clustering Algorithms
Các thuật toán phân cụm phổ biến nhất là:
Expectation Maximisation (EM – cực đại hoá kỳ vọng)
Hierarchical Clustering
k-Means
k-Medians
g. Những thuật toán luật phối kết hợp (Association Rule Learning Algorithms)
Đây là đầy đủ thuật toán sẽ rút trích ra các quy tắc giải thích tốt nhất mối dục tình giữa những biến trong dữ liệu. Những quy tắc này có thể giúp mày mò ra những tính chất đặc trưng và hữu ích trong các tập tài liệu lớn với cao chiều trong dịch vụ thương mại cùng các lĩnh vực khác. Hình 12 minh hoạ cho phát minh của thuật toán công cụ kết hợp.
Hình 12: Association Rule Learning Algorithms
Các thuật toán luật kết hợp phổ phát triển thành nhất là:
Apriori algorithm
Eclat algorithm
FP-Growth algorithm
h. Thuật toán mạng nơron tự tạo (Artificial Neural Network Algorithms)
Mạng nơron tự tạo là các mô hình được lấy cảm xúc từ cấu tạo và công dụng của màng lưới thần ghê sinh học. Hình 13 minh hoạ cho một mạng truyền thẳng.Nhóm thuật toán này rất có thể được thực hiện cho bài toán phân lớp và hồi quy với tương đối nhiều biến thể khác biệt cho phần đông các vấn đề. Mặc dù nhiên, trong bài viết này mình chỉ trình diễn các thuật toán cổ xưa và phổ biến nhất:
Back-Propagation (mạng lan truyền ngược)
Perceptron (Mạng viral thẳng)
Multi-layer perceptron (Mạng truyền thẳng đa lớp)
Hopfield Network
Radial Basis Function Network (RBFN)
Hình 13: Artificial Neural Network Algorithms
i. Thuật toán học sâu (Deep Learning Algorithms)
Thực hóa học Deep Learning là một bạn dạng cập nhật tiến bộ cho Artificial Neural Networks nhằm khai thác tài năng tính toán của máy tính, mặc dù vì sự cải tiến và phát triển lớn mạnh của chúng phải mình bóc ra thành một đội riêng.
Deep Learning cân nhắc việc xây dựng các mạng thần kinh bự hơn, phức hợp hơn nhiều, và làm thế nào để khai thác tác dụng các bộ dữ liệu lớn cất rất ít tài liệu đã được gán nhãn. Hình 14 minh hoạ cho phát minh của Deep learning.
Hình 14: Deep Learning Algorithms
Các thuật toán học tập sâu phổ cập nhất là:
Convolutional Neural Network (CNN)
Deep Belief Networks (DBN)
Deep Boltzmann Machine (DBM)
Stacked Auto-Encoders
j. Nhóm thuật toán bớt chiều tài liệu (Dimensionality Reduction Algorithms)
Giống như các phương pháp phân cụm, giảm không khí tìm kiếm với khai thác cấu tạo vốn tất cả trong tài liệu nhưng theo cách không đo lường hoặc nhằm tóm tắt hay mô tả tài liệu sử dụng ít thông tin hơn là kim chỉ nam của nhóm phương thức này. Hình 15 minh hoạ cho việc giảm chiều dữ liệu.
Xem thêm: Lớp tiếng anh đề án là gì - chương trình tiếng anh mới là bản sao đề án cũ
Điều này rất có thể hữu ích nhằm trực quan tiền hóa dữ liệu hoặc dễ dàng hóa dữ liệu mà sau đó có thể được áp dụng trong cách thức học bao gồm giám sát. Nhiều trong những các phương thức này có thể được kiểm soát và điều chỉnh để thực hiện trong phân lớp cùng hồi quy.
Hình 15: Dimensional Reduction Algorithms
Các thuật toán giảm chiều dữ liệu thịnh hành như:
Flexible Discriminant Analysis (FDA)
Linear Discriminant Analysis (LDA)
Mixture Discriminant Analysis (MDA)
Multidimensional Scaling (MDS)
Partial Least Squares Regression (PLSR)
Principal Component Analysis (PCA)
Principal Component Regression (PCR)
Projection Pursuit
Quadratic Discriminant Analysis (QDA)
Sammon Mapping
k. Thuật toán tập vừa lòng (Ensemble Algorithms)
Ensemble methods là những cách thức kết hợp các quy mô yếu hơn được huấn luyện hòa bình và phần dự kiến của chúng sẽ được phối kết hợp theo một bí quyết nào đó để lấy ra dự đoán tổng thể và toàn diện như minh họa sinh hoạt Hình 16.
Nhóm thuật toán này khá mạnh khỏe và được phân tích nhiều, nhất là về cách để kết thích hợp các mô hình với nhau.
Hình 16: Ensemble Algorithms
Một số thuật toán thông dụng như:
Ada
Boost
Boosting
Bootstrapped Aggregation (Bagging)
Gradient Boosting Machines (GBM)
Gradient Boosted Regression Trees (GBRT)
Random Forest
Stacked Generalization (blending)
l. Những thuật toán khác
Còn tương đối nhiều các thuật toán khác không được liệt kê làm việc đây, chẳng hạn như tư vấn Vector Machines (SVM), mình đang đắn đo rằng liệu thuật toán này yêu cầu được đưa vào team nào kia hay đứng một mình. Nếu phụ thuộc vào danh sách những biến thể cùng mức độ trở nên tân tiến thì SVM rất có thể được tách thành một đội riêng – nhóm thuật toán thực hiện véctơ hỗ trợ.
Thêm vào đó, các thuật toán được xuất hiện từ các nhiệm vụ quánh biệt, hoăc những thuật toán từ hồ hết nhánh con đặc biệt của ML cũng ko được liệt kê vào những nhóm, ví dụ điển hình như:
Feature selection algorithms
Algorithm accuracy evaluation
Performance measures
Có thời điểm mình sẽ bổ sung cập nhật hoặc đề cập đến các thuật toán này ở một nội dung bài viết khác.
Mặc cho dù rất hữu dụng (dựa vào nhóm, người tiêu dùng sẽ dễ dãi nhớ được bản chất của thuật toán) nhưng phương pháp phân đội này chưa hoàn hảo ở điểm gồm có thuật toán bao gồm thể tương xứng với nhiều hạng mục như Learning Vector Quantization, vừa là phương pháp lấy xúc cảm từ mạng thần kinh (neural network), vừa là phương pháp dựa trên thành viên (instance-based). Hoặc là thuật toán tất cả cùng tên mô tả câu hỏi và team thuật toán như Hồi quy (Regression) và Phân các (Clustering). Đối với các trường vừa lòng này ta rất có thể giải quyết bằng phương pháp liệt kê các thuật toán nhì lần hoặc bằng phương pháp chọn nhóm một cách chủ quan. Để tránh trùng lặp những thuật toán cùng giữ cho đều thứ đơn giản và dễ dàng thì có lẽ chọn nhóm theo cách chủ quan tiền sẽ phù hợp hơn.
Để giúp các bạn dễ nhớ cũng tương tự tổng kết cho phần này tôi đã vẽ một sơ đồ những thuật toán phân theo nhóm và thu xếp theo alphabet, các chúng ta có thể xem thểm sinh sống Hình 17 mặt dưới.
Hình 17: Sơ đồ phân team thuật toán theo sự tương đồng
Hy vọng nội dung bài viết này sẽ đưa về hữu ích cho mình đọc, độc nhất vô nhị là giúp cho bạn có dược ánh nhìn tổng quan tiền về phần nhiều gì hiện tất cả và một trong những ý tưởng về cách liên kết các thuật toán cùng với nhau.
Danh sách những nhóm và thuật toán được liệt kê trong bài viết chỉ đảm bảo an toàn được nhân tố phổ biến tuy vậy sẽ ko đầy đủ. Vậy nên nếu như khách hàng biết thêm thuật toán hoặc team nào không được liệt kê tại chỗ này hoặc của cả cách phân nhóm thuật toán khác, tương tự như sau khi phát âm mà các bạn có ngẫu nhiên góp ý, thắc mắc giúp cải thiện bài viết tốt hơn, các bạn cũng có thể để lại comment nhằm chia sẻ cùng mình với những độc giả khác nhé.
Tài liệu tham khảo:A Tour of Machine Learning Algorithms by Jason Brownlee in Understand Machine Learning Algorithms
Semi-Supervised Learning Tutorial by Xiaojin Zhu
https://en.wikipedia.org/wiki/Outline_of_machine_learning#Machine_learning_algorithms
Top 10 algorithms in data mining by Xindong Wu · Vipin Kumar · J. Ross Quinlan · Joydeep Ghosh · Qiang Yang · Hiroshi Motoda · Geoffrey J. Mc
Lachlan · Angus Ng · Bing Liu · Philip S. Yu · Zhi-Hua Zhou · Michael Steinbach · David J. Hand · Dan Steinberg.
Học thứ được giám sát và đo lường (supervised machine learning) là gì cùng nó liên quan ra làm sao đến học không đo lường (unsupervised)?
Trong bài bác đăng này, bạn sẽ tìm hiểu các khái niệm “học gồm giám sát”, “học ko giám sát” với “học sản phẩm có tính toán một phần”. Sau khoản thời gian đọc bài xích này, các bạn sẽ biết:
Các vụ việc về phân một số loại và hồi quy trong học tập máy có giám sát.Các vụ việc phân team và links trong kiểu dáng học không giám sát.Các ví dụ như được sử dụng trong các học máy tính toán và ko giám sát.Các vấn đề nằm giữa việc học có đo lường và ko giám sát, được gọi là học giám sát một phần.Học đồ vật được giám sát và đo lường (supervised machine learning)
Phần lớn những ứng dụng học máy thực tế đều áp dụng học tập có tính toán – supervised learning.

Học tập có giám sát và đo lường là nơi bạn có các biến đầu vào (X) với biến đầu ra (Y) với bạn thực hiện thuật toán để khám phá hàm ánh xạ từ trên đầu vào mang đến đầu ra.
Y = f (X)
Mục đích là để xây cất hàm ánh xạ một cách tốt nhất rất có thể để khi chúng ta có tài liệu đầu vào mới (X) và bạn cũng có thể dự đoán các biến cổng đầu ra (Y) cho dữ liệu đó.
Nó được gọi là vấn đề học bao gồm giám sát cũng chính vì quá trình của thuật toán học từ tập dữ liệu đầu vào hoàn toàn có thể được xem như là một “giáo viên” giám sát quá trình học tập. Họ biết câu vấn đáp đúng, thuật toán vẫn lặp đi lặp lại khiến cho việc dự kiến về tài liệu đầu vào thường xuyên được “giáo viên” trả thiện. Vấn đề học tạm dừng khi thuật toán có được mức năng suất ở mức chấp nhận được.
Việc học tập tập có giám sát hoàn toàn có thể được nhóm lại thành các vấn đề về phân một số loại và hồi quy.
Phân các loại (Classification): vấn đề phân loại diễn ra khi vươn lên là đầu ra là một trong những thể loại nào đó, ví dụ như “đỏ” hoặc “xanh” hoặc “bệnh” với “không có bệnh”.
Hồi quy (Regression): việc hồi quy xảy ra là khi biến hóa đầu ra là một trong những giá trị thực, ví dụ như “đô la” xuất xắc “trọng lượng”.
Một số các loại vấn đề thịnh hành được xây cất trên việc phân nhiều loại và hồi quy tương xứng với cơ chế gợi ý và dự kiến dãy thời gian.
Một số ví dụ thịnh hành của thuật toán học trang bị được đo lường là:
Hồi quy con đường tính cho các vấn đề hồi quy.Nguyên lý “Khu rừng ngẫu nhiên” cho việc phân các loại và hồi quy.Hỗ trợ các hệ máy vector cho những vấn đề về phân loại.
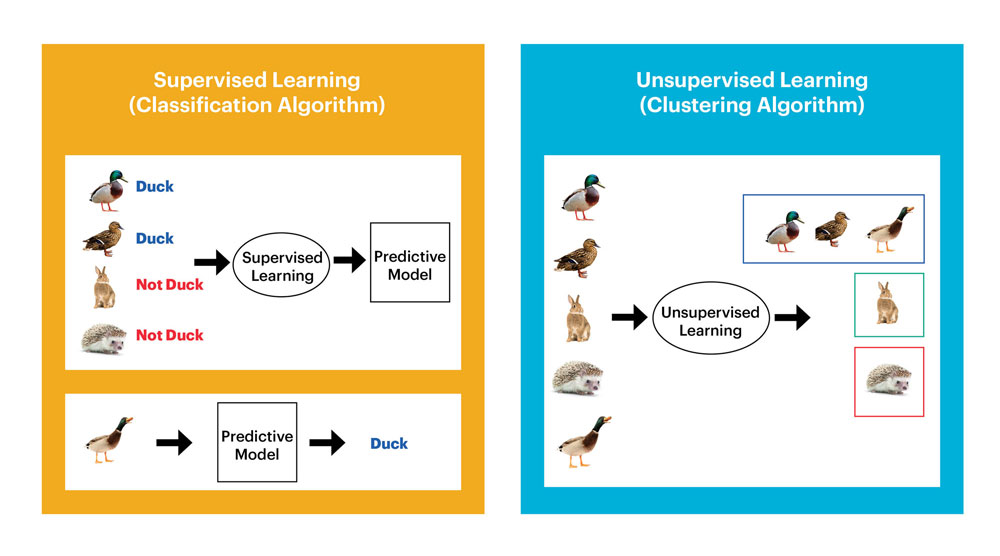
Học đồ vật không thống kê giám sát (unsupervised machine learning)
Học đồ vật không thống kê giám sát là nơi chúng ta chỉ có tài liệu đầu vào (X) và không tồn tại biến cổng output tương ứng.
Mục tiêu của việc học không tính toán là để quy mô hóa cấu tạo nền tảng hoặc sự phân bổ trong tài liệu để hiểu rõ hơn về nó.
Đây được gọi là học hành không đo lường và tính toán vì không y hệt như việc học có đo lường và tính toán ở trên, không tồn tại câu trả lời đúng và không có vị “giáo viên” làm sao cả. Những thuật toán được tạo ra chỉ để khám phá và biểu đạt các cấu trúc hữu ích bên trong dữ liệu.
Các vấn đề học tập ko giám sát có thể được phân ra thành hai bài toán chia nhóm cùng kết hợp.
Chia nhóm: vụ việc về phân chia nhóm là nơi bạn muốn khám phá những nhóm vốn có bên phía trong dữ liệu, chẳng hạn như phân nhóm người tiêu dùng theo hành vi cài hàng.
Kết hợp: vấn đề về học hành quy tắc phối hợp là nơi bạn muốn khám phá những quy tắc mô tả tài liệu của bạn, ví dụ như những người mua X cũng đều có khuynh hướng thiết lập Y.
Một số ví dụ phổ cập của thuật toán học không đo lường và tính toán là:
Xây dựng tham số “k-mean” cho vấn đề chia nhóm.Thuật toán Apriori cho các vấn đề tương quan đến việc học tập quy tắc.Học đồ vật giám sát một trong những phần (Semi-supervised machine learning)
Khi các bạn xây dựng quy mô trên một lượng lớn tài liệu đầu vào (X) cơ mà chỉ có một vài dữ liệu được dán nhãn (Y) được điện thoại tư vấn là vấn đề học tập có đo lường và tính toán một phần.
Nó nằm giữa việc học tập được đo lường và thống kê và không giám sát.
Ví dụ điển hình là một kho lưu trữ hình ảnh, nơi có một số hình ảnh được đính thêm nhãn, (ví dụ: chó, mèo, người) và đa số còn lại thì không được gắn nhãn.
Nhiều giải pháp học thứ trong thực tế rơi vào trường hòa hợp này. Điều này là vì việc gắn nhãn dữ liệu rất có thể gây tốn nhát hoặc tốn thời hạn và có thể đòi hỏi buộc phải tiếp cận được các chuyên gia trong lĩnh vực. Trong những khi đó, dữ liệu không có nhãn rẻ hơn các và dễ dàng thu thập, lưu giữ trữ.
Bạn hoàn toàn có thể sử dụng các kỹ thuật học hành không giám sát và đo lường để khám phá và tìm kiếm hiểu cấu tạo trong các dữ liệu đầu vào.
Bạn cũng có thể sử dụng chuyên môn học bao gồm giám sát để mang ra các phỏng đoán rất tốt cho dữ liệu không được thêm nhãn, cung cấp ngược tài liệu đó vào thuật toán học có đo lường và thống kê dưới dạng dữ liệu giảng dạy và áp dụng mô hình để lấy ra dự đoán về những dữ liệu đầu vào mới trọn vẹn khác.
Tóm tắt
Trong bài xích đăng này, chúng ta đã khám phá sự khác biệt giữa việc học gồm giám sát, không giám sát và được đo lường một phần. Bây chừ bạn vẫn hiểu:
Có giám sát: toàn bộ dữ liệu được dán nhãn và các thuật toán tìm hiểu để dự đoán cổng output từ dữ liệu đầu vào.Không được giám sát: toàn bộ dữ liệu ko được lắp nhãn và các thuật toán tra cứu hiểu cấu tạo vốn gồm từ tài liệu đầu vào.Giám giáp một phần: một số trong những dữ liệu được dán nhãn nhưng phần lớn dữ liệu còn lại không có nhãn và một láo lếu hợp những kỹ thuật có đo lường và tính toán và ko giám sát rất có thể được sử dụng.NTC Team lược dịch.








